Back to Blog
Zingtree Guardrails: How We Keep AI From Guessing in Complex CX
Learn how Zingtree’s three-layer guardrail architecture (intent detection, business rules, real-time context) prevents AI hallucinations and keeps CX automation safe, auditable, and compliant.
.webp)
10 min read


.svg)
.svg)
.svg)
AI hallucinations aren’t always obvious. They often look like “helpful” answers that are just slightly off. That’s what makes them risky.
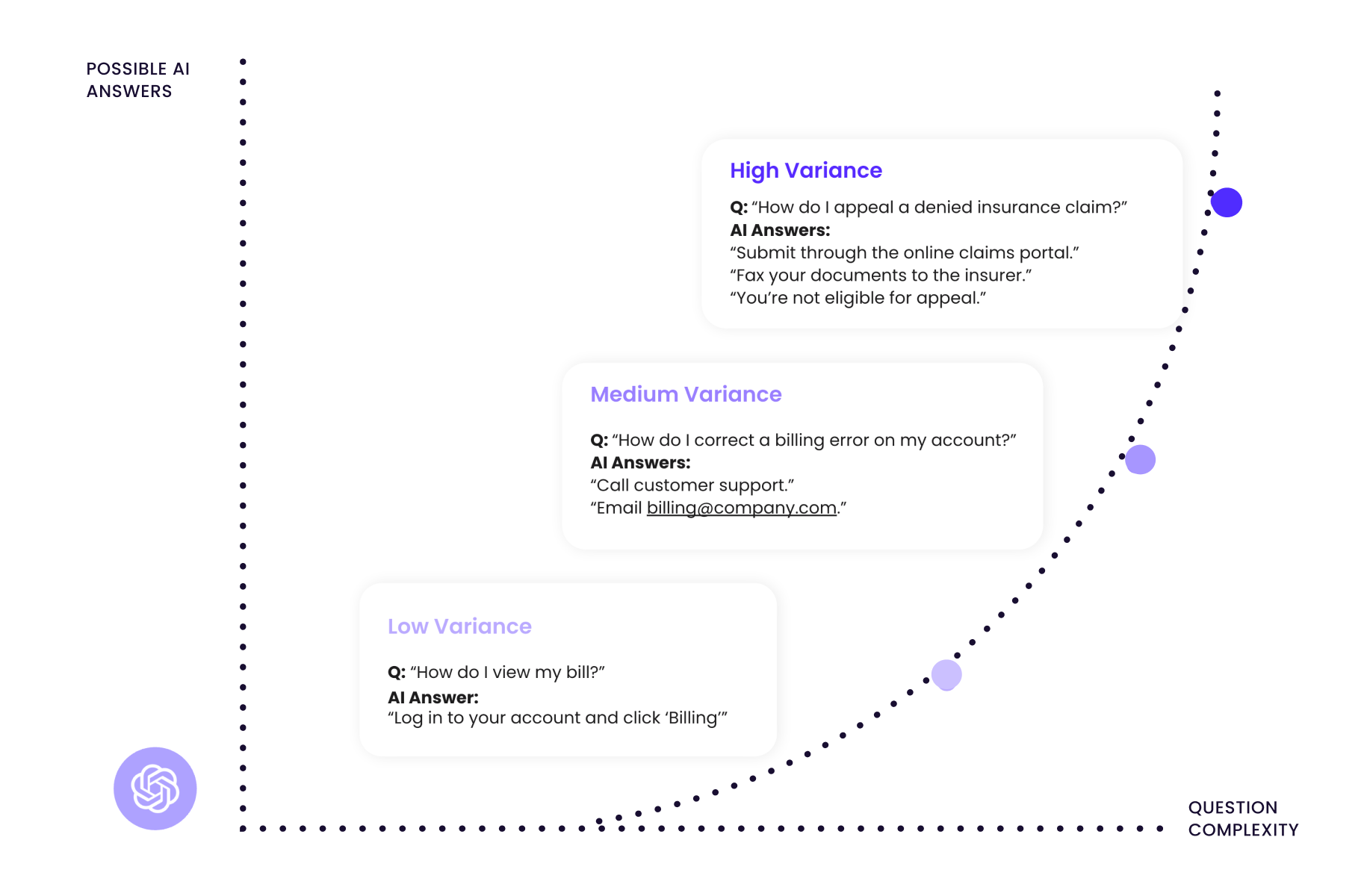
Why AI hallucinations are a critical risk in complex CX
In customer experience, hallucinations can lead to wrong policy guidance, unauthorized actions, or compliance violations.
Complex CX is uniquely vulnerable because the work is:
- Multi-step (handoffs, verification, eligibility, exceptions)
- Conditional (policy logic, edge cases)
- Cross-system (CRM + billing + policy + KB)
As those variables stack up, you get more variance in probable answers. And variance is where errors creep in.
That’s why complex questions are the real test for AI in CX. The model isn’t just retrieving a fact. It’s choosing a path. If you don’t constrain that path with guardrails, the model will fill gaps with guesses.
.png)
What guardrails mean at Zingtree: creating a funnel of control
AI guardrails are deterministic rules and controls embedded into an AI system’s architecture that constrain automated actions to approved, auditable boundaries. They prevent the model from acting outside defined parameters, ensuring outputs stay safe, accurate, and compliant.
Zingtree’s core design choice is deterministic AI for execution: actions are triggered by defined intent and human-authored decision logic, not model guessing.
The mental model is a funnel of control:
- Intent → filter what the user is asking
- Business Rules → pre- and post-generation controls that bound what AI can do
- Context → ground answers and actions in real-time systems data
This is the architecture described in Zingtree’s guardrails materials: you can use probabilistic AI to interpret language, but the “what happens next” must stay deterministic and auditable.
Guardrail 1: Intent detection to map user requests accurately
Intent detection is the process of classifying a user’s message into a predefined action category. Instead of letting a model freely interpret a request, intent detection maps input to a specific, supported workflow, ensuring only recognized actions proceed and ambiguous requests get clarified rather than guessed.
Example: “Cancel subscription” maps to cancel_and_refund, which triggers the exact policy logic for cancellation and refund eligibility.
What happens at the intent layer:
- Queries get mapped to predefined intents
- Irrelevant, incomplete, or unsafe inputs get filtered out
- Ambiguous inputs trigger clarification, not improvisation
- Out-of-guardrails requests route to human queues, not model guessing
Intent mapping examples
This layer is where deterministic AI starts. The model doesn’t “decide what to do.” It classifies and confirms.

Guardrail 2: Business rules with pre- and post-generation controls
Business rules guardrails operate like a two-stage gate:
- Pre-generation controls constrain what the model receives.
- Post-generation controls validate what the model produces.
This lines up with broader industry patterns: vendors talk about “guardrails,” but the meaningful difference is whether rules are enforceable before and after generation.
Pre-generation controls: setting parameters before AI action
Pre-generation controls are the input filter. They keep the model from ever seeing an unconstrained task.
Common controls:
- Link recognized intents to the correct rule sets and workflows
- Restrict which data sources can be used for that intent
- Set model parameters (temperature, top-p) to limit speculative output
- Structure prompts so the model stays inside scope
Simple flow: User input → intent classification → pre-generation filtering → structured prompt to model
This is how you prevent hallucinations at the source. The model never gets the chance to freestyle.
Post-generation controls: confidence scoring and human escalation
Confidence scoring is a real-time evaluation mechanism that assigns a numerical score to an AI-generated output based on how certain the system is about accuracy. Outputs below a defined threshold are blocked from delivery and routed to a human agent for review, preventing uncertain answers from reaching the customer.
Confidence-style validation is a common pattern in guardrails tooling (example: “trustworthiness” scoring and output validation approaches in NVIDIA NeMo Guardrails + Cleanlab, and formal verification checks in AWS).
Zingtree uses escalation routing so “uncertain” does not reach the customer as a confident answer.
Confidence routing table
A practical best practice from CX risk guidance is to make these thresholds deterministic. Example: if an agent can offer a discount, hard-cap it (like “never exceed 15%”).
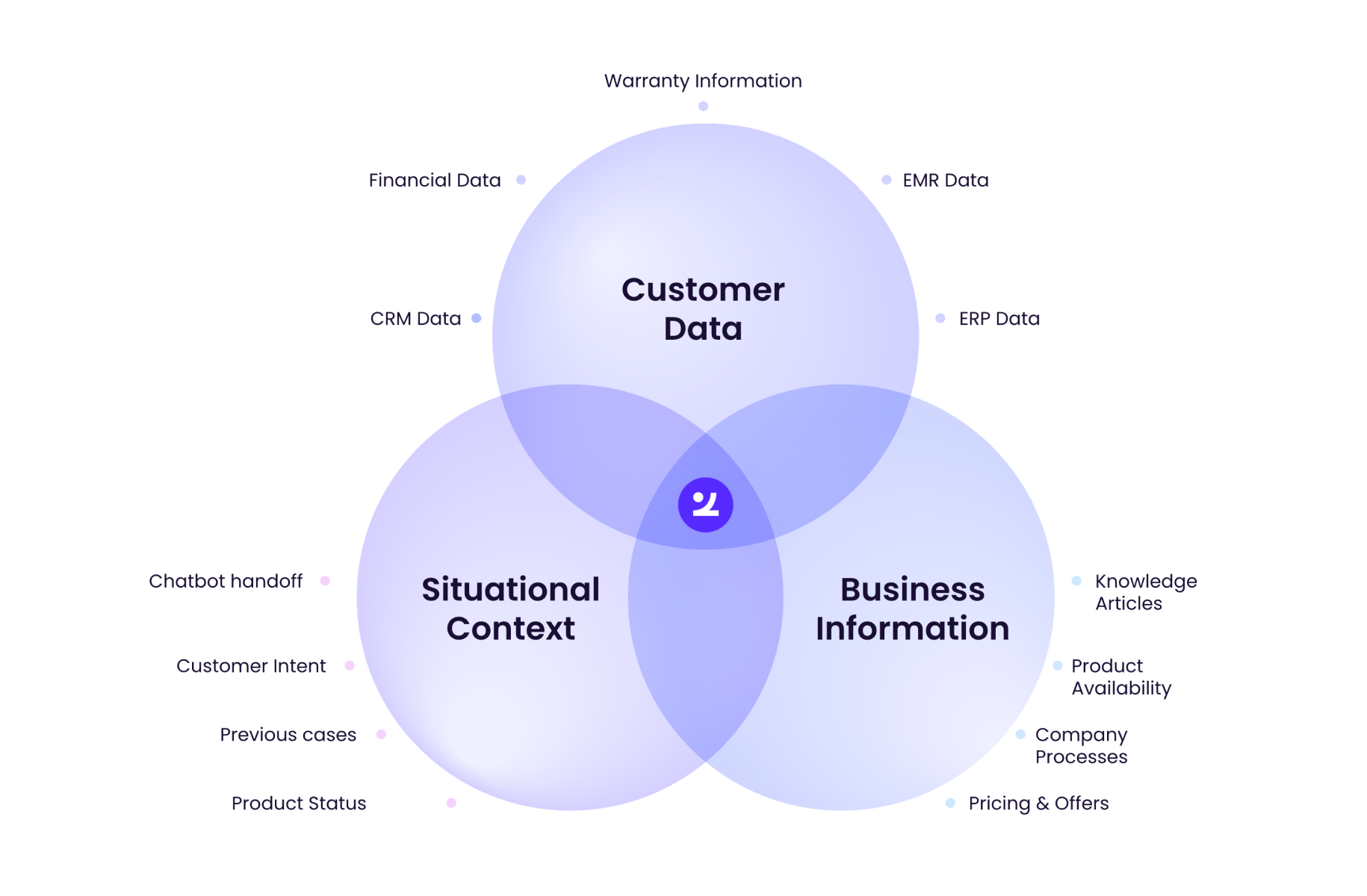
Guardrail 3: Context integration from real-time systems and data
Context integration is the process of pulling live, verified data from connected business systems, such as CRM, billing, and policy databases, into an AI workflow at the moment of decision. This ensures the AI responds based on the customer’s actual account state.
Zingtree’s guardrails framing explicitly calls out real-time system pulls (billing, plan type, eligibility) so decisions are gated on “what’s true right now.”
What context integration prevents:
- Answering from generic training data instead of the customer’s actual situation
- Offering actions the customer is not eligible for
- Citing outdated policy language
Common connected sources:
- Billing and payments
- CRM and profile data
- Policy and regulatory databases
- Knowledge base and product doc
- Entitlement and eligibility engines
How Zingtree’s end-to-end control loop enforces safe AI decisions
Here’s the end-to-end loop (this is the “funnel of control” operationalized):
- Customer submits a query
- Intent detection classifies to a supported action
- Pre-generation controls bind scope, rules, and allowed data
- Context integration pulls real-time account and policy data
- AI generates a response inside constrained parameters
- Post-generation controls validate with confidence scoring
- High-confidence executes; low-confidence escalates to a human
- Every step is logged and audit-ready (version-controlled decision paths)
Zingtree also publishes scale and adoption metrics that matter to CX operators: 700+ organizations and 50+ countries on the platform. And Zingtree has reported processing 162M+ customer interactions.
Practical workflow examples demonstrating guardrail impact
Below are three common high-stakes CX scenarios. Same format each time: Scenario → Intent → Business Rules (Pre/Post) → Context → Outcome
1. Refund eligibility determination
Scenario: Customer asks for a refund on a recent charge.
- Intent: “I want my money back” → cancel_and_refund
- Pre-generation rules: bind to refund policy logic, restrict responses to allowed outcomes
- Context: pull live billing data, plan type, eligibility flags
- Post-generation: confidence score gates approval vs escalation
- Outcome: process refund only if eligible; otherwise route to a human with full context
2. Claim dispute resolution (insurance or fintech)
Scenario: Policyholder disputes a denied claim and asks the AI to reverse it.
- Intent: “My claim was wrongly denied” → claim_dispute_review
- Pre-generation rules: restrict the AI to collecting required info + presenting dispute paths, not reversing decisions
- Context: pull claim status, policy coverage, adjudication notes
- Post-generation: borderline cases drop confidence and escalate
- Outcome: the AI does not promise outcomes it can’t deliver
3. Identity verification process (HIPAA, KYC/AML)
Scenario: Customer requests sensitive account changes (password reset, beneficiary change, address update).
- Intent: “Update my account” → identity_verification_required
- Pre-generation rules: enforce mandatory verification steps before any access or change
- Context: validate identity status (MFA, security questions, account flags)
- Post-generation: failed or incomplete verification forces escalation
- Outcome: no sensitive access is granted prematurely
Evaluating safe AI: what Directors should look for in guardrails
Most vendors say “we have guardrails.” Directors need to know if the guardrails are structural or cosmetic.
Use this checklist:
Red-teaming, simulation, and “use AI to judge AI” are common recommendations for de-risking AI agents in CX.
If your current platform can’t meet these criteria, you don’t have enforceable AI governance. You have prompts and hope.
Frequently asked questions
What are the main guardrails that prevent AI hallucinations?
Intent detection (classify requests to supported actions), business rules (pre- and post-generation controls), and context integration (grounding in real-time system data). Together, they keep AI bounded, verified, and auditable.
How do confidence scores influence AI workflow decisions?
They gate execution. High-confidence outputs can proceed. Medium confidence triggers clarification. Low confidence blocks delivery and routes to a human.
Why is real-time context essential for accurate AI responses?
Because it forces responses to reflect the customer’s actual account state (eligibility, billing, coverage), not generic assumptions. It reduces hallucinations caused by missing facts.
How can ops teams maintain and audit AI guardrails?
Look for no-code rule ownership, version control, and exportable logs so ops and compliance can prove what happened, when, and why. (This is the core of “auditable workflows.”)
What are best practices for deploying guardrails in regulated industries?
Start narrow, simulate at scale, red-team before launch, keep humans in the loop for edge cases, and set hard deterministic thresholds for business risk.
.png)

